InnoDB是如何存储数据的
本文最后更新于:2022年7月3日 下午
InnoDB 怎么存储数据
数据目录
众所周之,MySQL 的数据是存储在硬盘中的,而操作系统管理硬盘中的数据的方式就是文件系统,所以通俗的来说,MySQL 中的数据是存在一个个文件中的,这些文件 的目录就叫 数据目录。
通过 SHOW VARIABLES LIKE 'datadir' 可以查看这个目录:
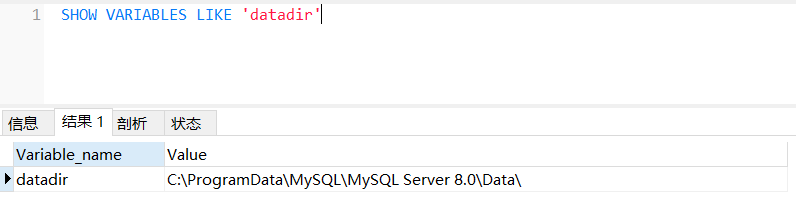
进入这个目录,你会发现,每个数据库对应该目录下的一个子目录,比如 MySQL 中有一个 hotsong 的库,Data 目录下就会有一个 hotsong 的文件夹,这个文件夹里面存储的是一些 ibd 类型的文件,数据库里每张表对应一个 ibd 文件:
1 | |
这里是 MySQL 8.0 的样子,但如果你使用的是更早的版本,你还会看到一种 .frm 的文件,这种文件用来描述表结构,8.0 之后, 表结构信息以 SDI 的形式放在了 .ibd 文件中,你可以使用官方提供 的工具 idb2sdi 从 ibd 文件中提取表结构信息,结果会以 json 形式输出
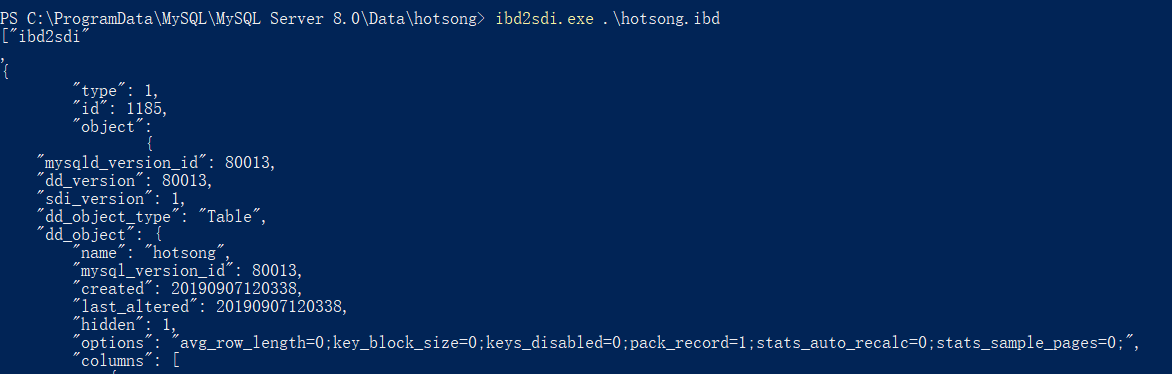
在 8.0 之前,ibd 文件里保存的仅仅是该表的数据,但是再往前,MySQL 5.6.6 之前,MySQL 服务器中所有表的数据都会被放在一个地方,叫系统表空间, 对应数据目录下的 ibdata1 文件,这是一个自扩展文件,但是你也可以在服务器启动时使用相关参数指定服务器使用自定义的文件。
在 5.6.6 之后,InnoDB 引如 独立表空间 空间的概念,每张表使用单独的文件存储数据和表结构,也就是上面的 ibd 和 frm 文件,服务器启动时,可以通过 innodb_file_per_table 设置只使用系统表空间(值为 0)或者是使用独立表空间(值为1).
服务启动后,通过 ALERT 语句,存储在两种表空间中的数据可以相互移动。
需要注意的是,不是说使用了独立表空间系统表空间就没用了,因为系统表空间除了可以存储表数据外,还存储了许多 MySQL 服务运行所必要的公共信息。
数据目录总结
MySQL 的数据是存储在磁盘的,或者可以说是存储在文件中的,这些文件的目录叫做数据目录,每个数据库对应数据目录下的一个子目录,每个表中数据存放的地方叫表空间,在 5.6.6 之前,所有数据都被存放在一个地方,叫系统表空间,数据库子目录下只有 frm 文件,用来描述表结构,在 5.6.6 之后,InnoDB 默认将每个表的数据放在一个单独的 ibd 文件中,称为独立表空间,在 8.0 之后,InnoDB 将描述表结构的 frm 信息以 sdi 的形式也放在了 ibd 文件中,所以 8.0 之后,数据库子目录下就只有 ibd 了。
5.6.6 之后,系统表空间默认只存储一些必要的公共信息,对应数据目录下的 ibdata1 文件,但他仍然很重要。
InnoDB 的数据存放在数据目录下的某个文件中,这是把 InnoDB 看作一个黑盒,从操作系统的角度得到的一个宏大的结论,但每条记录是以怎样的形式组织在这个文件中的,就需要深入了解表空间和记录的具体结构了。
聚簇索引和页
众所周之,InnoDB 中每张表都一定会有一个聚簇索引,如果该表设置了主键,那就会以主键建立聚簇索引,如果没有设置主键,InnoDB 会选取一个唯一非 NULL 的列建立聚簇索引,如果找不到适合建立聚簇索引的列,InnoDB 会给表插入一个隐藏列 row_id, 并以此建立聚簇索引。
为什么 InnoDB 如此执着非要建一个聚簇索引呢?原因是聚簇索引的叶子节点会存储表中的完整数据,换句话说,InnoDB 中的数据是存储在聚簇索引叶子节点中的。
InnoDB 的聚簇索引是一颗 B+ 树,B+ 树的每个节点占一页,“页” 是 InnoDB 中内存分配的基本单位,大小为 16KB,InnoDB 中有许多不同种类的页,如移除页,索引页等,B+ 的树节点类型就是索引页,它的结构如下图所示:
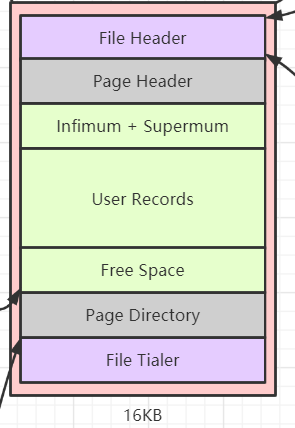
从上往下依次是:
- 文件头(File Header):占 38 字节,用来描述数据页的一些状态信息。
- 页头(Page Header): 占 56 字节,记录了存储在页中的记录的一些状态。
- Infimum + Supermum: 占 26 字节,该页中两条预添加的记录,Infimum 表示该页中的最小记录,Supermum表示一个最大记录。
- User Records: 用户记录。
- Free Space: 空闲空间。
- 页目录(Page Directory): 用来加快页内记录查找速度。
- 文件尾(File Tialer): 用于校验数据。
File Header
文件头(File Header):占 38 字节,用来描述数据页的一些状态信息,它的结构如下:

从左到右依次表示:
- 该页的校验和
- 页号
- 上一个页的页号
- 下一个页的页号
- 页面被最后修改时对应的日志序列号(LSN)
- 页面类型
- 仅在系统表空间的第一个页上使用
- 页属于哪个表空间
这里面比较重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT ,这两个字段可以看作指向上一个页和下一个页的指针,我们知道 B+ 树的叶子节点是通过双指针串联起来的,但实际上,InnoDB 的索引里,它的非叶子节点也可以看作是串连起来的。
Page Header
页头(Page Header): 占 56 个字节,他记录了存储在页中的记录的一些状态,结构如下:

从上到下依次为:
- 页目录中槽的数量(后面会说)
- 还未使用的最小地址空间,也就是该地址之后就是 Free Space 了。
- 第一位表示本记录是否为紧凑型记录,后 15 为表示本页堆中的记录数。
- 已删除记录链表的头节点的偏移。
- 已删除的记录占用的字节数。
- 最后插入的记录的位置。
- 记录插入方向。
- 一个方向连续插入的记录数。
- 用户记录数(PAGE_N_HEAP 中的记录数包含已经删除了的记录和Infimum + Supermum, 但这里不包含)
- 当前页的最大事务 ID。
- 该页在 B+ 树中所处的层级。
- B+ 树叶子节点的头部信息(只在 B+ 树的更页面定义)
- B+ 树非叶子节点头部信息(只在 B+ 树的更页面定义)
关于第一个 PAGE_N_DIR_SLOTS , 他与页目录有关,在后面会说到,关于 3, 4, 5, 9 他们都涉及到了记录的删除,当我们执行 DELETE 语句时,InnoDB 并不会真的把这条记录从磁盘删除,因为这还涉及到紧凑数据,每次都真正删除花销太大,所以 InnoDB 会修改这条记录上的一个标记位,并将这些已经删除的记录链在一起(事实上正常记录也是链在一起的,在说记录格式时会讲到),4 PAGE_FREE 所记录的就是这个链表的头节点在 User Records 中的偏移。
关于 7,8,记录插入方向描述的是新插入记录的主键值与最后一次插入记录主键值的大小关系。
User Records
到这儿就需要说一下 InnoDB 的记录行格式了。
InnoDB 行格式
行格式,也就是每条记录在 InnoDB 中的真实样子,InnoDB 有四种行格式,分别是:COMPACT, REDUNDANT, DYNAMIC, COMPRESSED,通过 ROW_FORMAT 可以修改表的行格式,如:
1 | |
这里以 COMPACT 格式为例,它的结构如下:
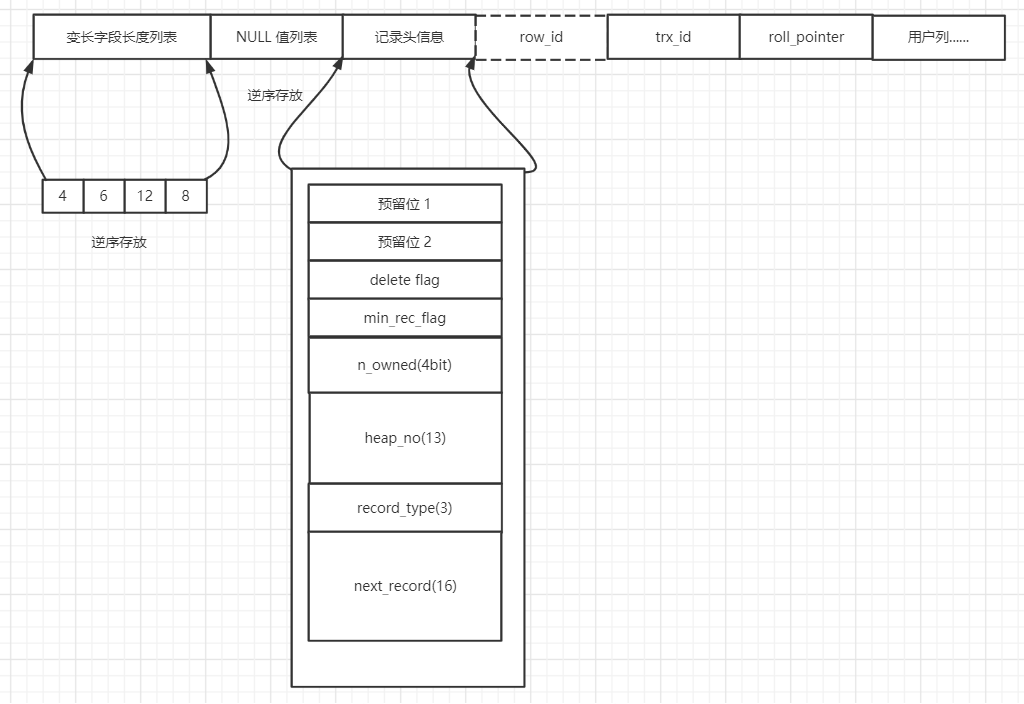
变长字段长度列表
顾名思义,这个结构用来存储这一行里变长字段的长度,唯一需要注意的是这个列表是按表结构逆序排序的,假如一个表结构如下:
1 | |
其中 name, download_link, singer 的类型是 varchar, 属于变长字段,如果向该表中插入一条记录,其中 name, download_link, singer 的长度分别为 1, 2, 3, 则在变长字段长度列表中会存储 3, 2, 1。
对于列表中该使用多少字节存储一个字段的长度,这取决于表采用的字符集和该类型能存储的最大字节数,如上表,字符集是 utf8mb4, 该字符集最多使用四个字节表示一个字符,而定义中, name 最多存储 50 个字符,所以这些字段能存储最多 4 * 50 = 200 字节的数据,所以用一个字节就可以表示其长度了,而 download_link 最多存储 100 个字符,则需要两个字节来表示其长度了。这里最多也只会使用两个字节,如果某个字段长度特别长,就需要使用溢出字段了,也就是在这一页中只会存部分数据。
变长字段列表只会存不为 NULL 的列的长度,NULL 列会表现在下面的 NULL 值列表中。
NULL 值列表
很好理解,NULL 值列表类似于一个 BitMap 表明了这一行中哪写列是 NULL,这些为 NULL 的列是不会占额外的空间的,存记录时, InnoDB 会去查看表格式,看允许为 NULL 的列有多少个,如上面的 hotsong 表,只有两个字段允许为 NULL,那 NULL 值列表就会占用一个字节(必须占用整数字节,高位填0),最低两位用来表示 singer 和 download_link, 这里和长度列表一样,也是逆序排列的,值为 0 时,代表该字段不为 NULL。
记录头信息
记录头信息里,我们暂且关注这几个字段:
delete_flag: 标识这条记录是否被删除,在 Page Header 那已经说过了,这就是那个标志位,为 1 表示被删除。n_owner: 与页目录有关,页中的记录会被分成若干组,这个字段表示这一组中的记录数。heap_no: 这条记录在页堆中的偏移。```
record_type1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
: 记录类型:
- 0: 普通记录
- 1:B+ 树非叶子节点目录项记录
- 2:Infimum 记录
- 3:Supermum 记录
- `next_record`: 下一个记录(主键大小上的下一条)的相对位置,通过这个字段,页面中的每条记录都像是使用链表连起来了。
回到索引页的 User Records 上,通过上面行格式的介绍,我们知道每一条记录的长度是不一样的,并且他们通过 `next_record` 链在了一起,所以记录在 User Records 中是像下面这样存储的:
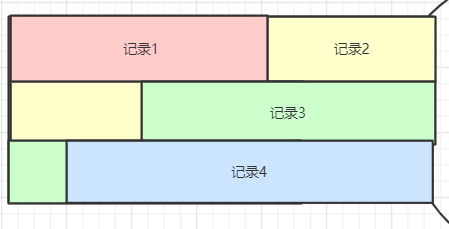
记录一条一条紧密排列,这个结构被称之为 Heap(堆), 记录在这个堆中的相对位置就是上面记录头信息里的 `heap_no`, `next_record` 指的也是下一条记录的偏移,而不是真的一个链表指针。
除此之外,InnoDB 的设计者在每一个堆中加入了两条特殊记录:Infimum 和 Supermum,他们的 `heap_no` 分别为 0 和 1,这两条记录很简单,只有记录头信息和代表这两个单词的记录体,这两个特殊记录代表了这一页中最大和最小的记录,也就是说,通过 Infimum 的 next_record 找到的是堆中的第一条用户记录,堆中的最后一条用户记录的 next_record 指向了 Supermum, 如果把紧密排列的堆变成链表的样子,他应该是这样的:
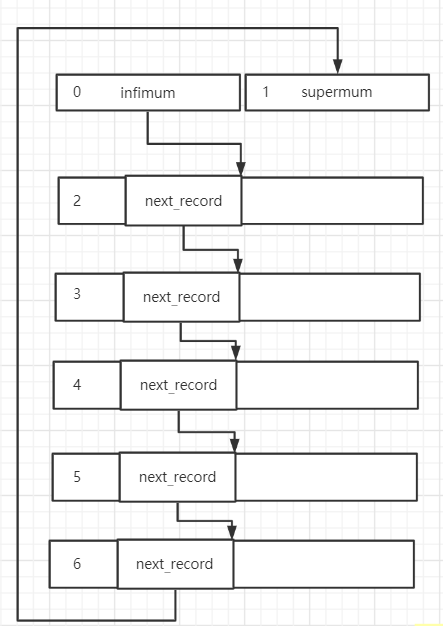
关于 `next_record` 他还有一个非常重要的特性,就是它允许为负,表示当前记录的下一条记录在它前面,这里的下一条是主键大小排列上的下一条,比如页中有一个主键值为 5 的记录 A(长度为 len_A*l**e**n**A*),我们又插入了一条主键值为 6 的记录 B(长度为 len_B*l**e**n**B*),那么 A 的 next_record 就是 +len_A+*l**e**n**A* 表示沿着记录 A 向后寻找 len_A*l**e**n**A* 个字节就是记录 B,但这时如果我们又插入了一条主键值为 4 的记录 C,那 C 的 next_record 就是 -(len_A + len_B)−(*l**e**n**A*+*l**e**n**B*) 也就是向前找能找到 C 的下一条记录 A。
这样的好处是通过 `next_record` 页中的所有记录会组成一个按主键排序的有序链表,但在物理上,记录还是按插入顺序紧密排列的,配合下面的页目录,能提高页内记录的检索速度。
### Page Directory
我们知道,索引的存在是为了快速定位到记录所在的页,但定位到页后呢,一页里可能包含许多记录,遍历页中的所有记录同样是不可接受的,所以 InnoDB 设计了页目录,相当于页索引,它的工作原理如下:
1. 将所有未删除的记录(包括Infimum 和 Supermum)划分为多个组。
2. 将每组中的最后一条记录的偏移提取出来放在 Page Directory 中。
3. 当查找页中的某条记录时,先通过二分法查找到该记录在哪一组中,然后找到这一组中最小的那条记录,沿着 next_record 往下遍历这一组的记录。
这里 Page Directory 中的每一个偏移量被叫做一个 **槽**, 一个槽占 2 字节,记录分组的原则是:
- Infimum 独占一组
- Supermum 那一组只能有 1~8条记录
- 其他组只能有 4 ~ 8 条记录
这样一来,页中最多遍历 8 次,就可以找到(确认找不到)某条记录了,能这样做的前提,还是通过 `next_record` 记录组成了一个有序链表。
还有一个有趣的问题,槽中记录的是一组中最大的记录的偏移,但定位到组后,需要的是最小的记录,该怎么办呢?上一个槽的下一条记录不就是吗。
### 总结
第一节 **数据目录** 我们站在操作系统的角度,说 InnoDB 是把数据存储在数据目录下的文件中的,这一节,我们从聚簇索引的一个节点(页)出发,说明了一条记录是怎样被存放的,关键点如下:
1. 所有数据被存放在表聚簇索引的叶子节点上。
2. 索引的一个节点就是一页,大小为 16KB,页是 InnoDB 内存分配的基本单位。
3. InnoDB 中,页有很多种,索引的节点对应的页类型叫索引页。
4. 索引页由文件头,页头,用户记录,页目录,文件尾等部分组成。
5. 通过文件头,页和页可以以双链表的形式连接起来。
6. 页头记录了页中的一些统计信息。
7. 用户记录段是存储用户记录的地方,每条记录被紧密地存储在这,称为堆。
8. 每条用户记录都有一个重要的 `next_record` 字段,他能保证紧密排列地用户记录能按主键大小组织成一个有序链表。
9. 有两条特殊的记录 Infimum 和 Supermum被安排在堆中,他们处于堆中最前的位置,但分别表示最大最小的记录。
10. 页目录是为了提高页内记录检索的速度而存在的,堆中的记录最多会 8 个为一组,每一组中最大的记录偏移量会被存放在页目录中,称为槽,查找记录时,会先通过二分法定位到组,然后在组内遍历。
11. 文件尾用来校验数据。
最后,放上索引页的整体图:
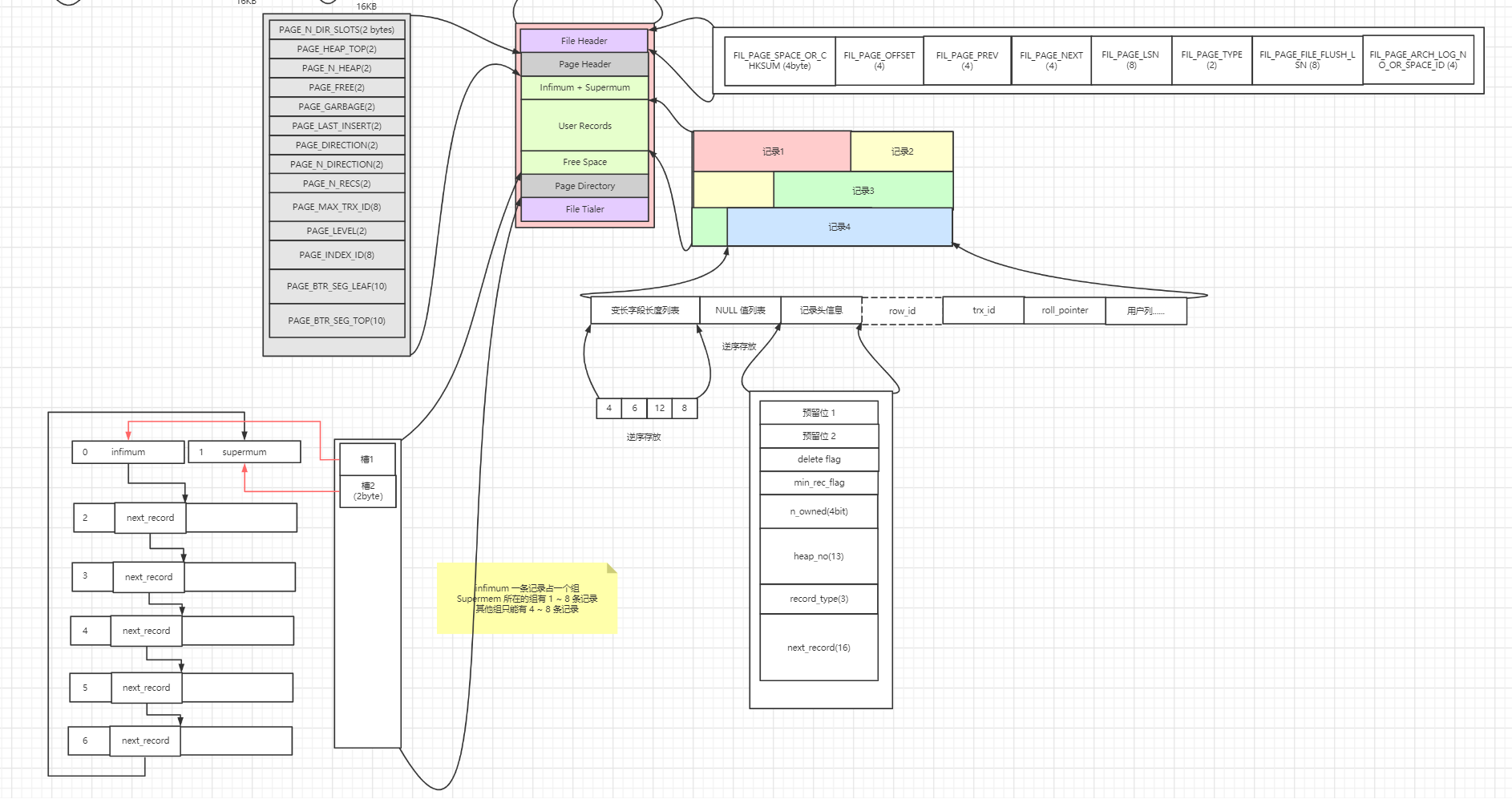
接下来,我们要把页和数据目录结合起来,了解页是怎么在表空间中组织的。
## InnoDB 表空间
在 MySQL 5.6.6 之后, InnoDB 有了独立表空间的概念,每张表对应一个独立表空间(一个 ibd 文件),而系统表空间(ibdata1)则主要用来存储一些公有的信息,这一节,我们以页为单位,看一看 InnoDB 是怎么在表空间中管理每个页的。
### 页回顾
上面多次说过,页是 InnoDB 分配内存的基本单位,一页大小 16KB,页有许多不同的类型,如:
- Index 页,上面已经说过。
- Inode 页,用来存储段信息。
- XDES 页,存储区信息。
- FPS_HDR 页,存储表空间头部信息。
- IBUF_BITMAP 页:存储 Change Buffer 相关的内容。
除了这几个,其实还有许多种类型的页,但其余的和本文关系不大,我们只关心这几种页就好了。
上面说 Index 页时讲了它的格式,事实上,`File Header` 和 `File Trailer` 是所有页面类型所共有的,在后面介绍其他页面类型的结构时,就不赘述了。
### 区 , 组和段
前面说过,页是 InnoDB 分配存储空间最小的单位,但问题在于页太小了,只有 16KB,在表中数据非常多时,如果继续以页为单位分配,就可能造成页与页间的物理距离过大,虽然页和页之间是通过指针连接的,但在使用传统机械硬盘时,物理距离大就意味着根据一个页的 Next 指针找到下一个页磁头需要移动更多的距离(随机 IO),造成页和页虽然在逻辑上连续,但在物理上分散,这样不利于高效地数据读写。为了尽量避免这种情况,InnoDB 会尽量让逻辑上相连的页在物理内存上也连续(顺序IO),具体做法就是当表中的数据量很大时,就以更大的 **区(extent)\**为单位为表分配存储空间,InnoDB 规定连续的 64 个页是一个区,也就是一个区占 1M 的空间。同时,为了方便管理这些区,将连续的 256 个区被划分为一\**组**,每一组的开始几个页面类型是固定的:
对于表空间中第一个组的前三个页面类型是固定的,他们依次是:
1. FPS_HDR 页:记录表空间的整体属性和这一组中 256 个区的整体属性。
2. IBUF_BITMAP 页:存储 Change Buffer 相关的内容。
3. INODE 页:存储与段相关的内容。
对于其他组,它的前两个页面类型是固定的,依次是:
1. XDES 页:记录这一组中说有区的属性
2. IBUF_BITMAP 页:存储 Change Buffer 相关的内容。
所以独立表空间的结构类似于下图:

蓝色的表示一个组,大小为 256 MB, 绿色的表示一个区,大小为 1M, 红色的表示一个页,大小为 16KB。
##### 段
> 区存在的意义是尽量让页面链表中相邻的页在物理位置上也相邻,这样在扫描叶子节点的大量记录时,才可以使用顺序IO。
引入区是为了加快扫描叶子节点时的速度,但事实上不管是叶子节点还是非叶子节点,他们的页类型都是 Index, 非叶子节点间也是有链表连起来的,只是我们一般用不到这些指针而已,所以如果把叶子节点和非叶子节点都放在区里面,扫描的性能又会大打折扣了,为此,InnoDB 引入了**段**,这是一个逻辑上的概念,每个索引(聚簇索引或二级索引)都有两个段,分别用来存放叶子节点和非叶子节点。
当表中的数据很少时,段会以页为单位申请存储空间,这些零散的页所在的区叫做**碎片区**,它直属于表空间。当表中的数据占了 32 个零散的页面后,段会以完整的区为单位分配存储空间,但之前存储在零散页面的数据并不会被移动过去。这样做的目的是尽量减少浪费。
所以**段是一些零散的页面以及一些完整的区构成的集合**。
##### 区的分类
有了段后,区就可以被分为下面几类:
1. 空闲区(FREE):完全没有被使用的区。
2. 有空闲的碎片区(FREE_FRAG): 区中的部分页面被用作段的零散页面,但还有空闲的页。
3. 无空闲的碎片区(FUEE_FRAG): 所有页面都被用了的碎片区。
4. 完整分配给某个段的区(FSEG):当表中的数据占了 32 页后,段会以完整的区为单位分配空间,这些区就是 FSEG。
##### XDES Entry
为了管理这些区,InnoDB 设计了一个大小为 40 字节的 `XDES Entry` ,它的结构如下:
| XDES Entry 结构 | List Node 结构 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |
- Segment ID: 对于一个 FSEG 类型的区,Segment ID 用来标识它被分配给了哪个段。
- List Node: 通过这个结构,XDES Entry 能连成一个链表。
- Prev Node Page Number, Prev Node Offset: 上一个 XDES Entry 所在的页面和在页面内的偏移,通过这两个字段,可以在表空间中找到上一个 XDES Entry.
- NextNode Page Number, Next Node Offset: 下一个 XDES Entry 。
- 这个链表链接的是**相同状态的区对应的 XDES Entry**, 也就是说,如果一个 XDES Entry 对应的区是 FREE 状态的,那么根据它的 Next 和 Prev 指针拿到的 XDES Entry 对应的区也是 FREE 状态的。如此一来,不同类型区对应的 XDES Entry 就会被组织成不同的链表,通过这些链表的头节点(保存在固定的地方),我们就可以快速获得一个需要的区或碎片页(由于 FSEG 类型的区已经分配给段了,所以这里的链表不包括这种类型的,FSEG 类型的区会在段内链接成别的链表,马上会说到)。
- State:表示这个区的状态。
- Page State Bitmap: 没两位对应区中的一页的状态, 00 表示这一页空闲, 01表示不空闲。
有了 XDES Entry 后,向表空间申请页插入新记录的的过程就是这样的了:
1. 如果表中数据不多(不足 32 页),就从 FREE_FRAG 链表中找到一个 FREE_FRAG 状态的区,并通过 Page State Bitmap 找到一个空闲的页分配给表(实际上是分配给索引或者说分配给段)之后把记录插进去,如果没有 FREE_FRAG 状态的区,就通过 FREE 链表找到一个 FREE 状态的区,将其中的一页分配给段,并将这个区对应的 XDES Entry 从 FREE 链表移动到 FREE_FRAG 链表中。
2. 如果表中的数据到了 32 页,就需要以区为单位给段分配空间,这时只需要根据 FREE 列表找到一个 FREE 分配给段即可。
##### Inode Entry
类似于 XDES Entry,InnoDB 为每个段设计了一个 Inode Entry 结构,这个结构记录了该段的一些必要信息,它的结构如下:

上面说过,段是由一些整块的区和一些零碎的页组成的逻辑上的结构,Inode Entry 记录的就是这些信息,对于段中整块的区,InnoDB 将其分成了三类:
- FREE 区:完全没有使用的区,刚刚分配的。
- NOT_FULL 区:还有空页面的区。
- FULL 区:没有空页面的区。
这三类区对应的 XDES Entry 结构也会组成一个链表(从上面的区的分类来看,他们都是 FSEG 类型的),Inode Entry 中的 List Base Node For FREE List, List Base Node For NOT_FULL List, List Base Node For FULL List 对应的就是这三个链表的头节点, NOT_FULL_N_USED 字段储存的就是 NOT_FULL 链表中已经使用了多少页面了。
Magic Number 字段用来标记 Inode Entry 是不是已经被初始化了,值为 97937874 时,表示已经初始化了(确实是 Magic Number)
下面的 32 个 Fragment Array Entry 每个占四字节,用来存储段中 32 个零碎页的页号。
Segment ID 用来记录这个段的唯一 ID。
##### 小结
页是分配存储空间的最小单位,但页太小了,在数据量特别大时,如果依然以页为单位分配,可能导致逻辑上相邻的两个页在物理上相隔很远,这样在遍历叶子节点时就会造成大量的随机 IO,为此,InnoDB 规定当表中数据占用空间小于 32 页时,从碎片区中以页为单位分配,当超过 32 个页后,就以更大的区(连续的 64 个页)为单位分配存储空间,每个区由一个 XDES Entry 结构管理,不同状态的 XDES Entry 结构通过 List Node 链接成一个链表,也就看一看作是不同状态的区链成了不同的链表,在分配区或碎片页时,就可以直接从对应链表获取到对应的区了。
为了进一步减少随机 IO,InnoDB 还引入一个逻辑上的概念 “段”,每个索引对应两个段,分别是叶子节点段和非叶子节点段,每个段实际上是一些碎片页和一些整块的区(FSEG 状态)的集合,每个段由一个 Inode Entry 结构管理,在段里,完整的区也会被分成三类,每类使用单独的链表链接。
### 页面类型
上面说的 XDES Entry, Inode Entry 是被存储在特定的页面类型中的,他们分别是 `XDES 页`, `Inode 页` 和 `FSP_HDR 页`, 他们的结构如下:
| XDES 页 | INODE 页 | FPS_HDR 页 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|  |  |  |
除了熟悉的 XDES Entry 和 Inode Entry 外, File Header 和 File Tialer 是所有页面共有的,在索引页那已经说过,剩下的就是 INODE 页的 `List Node For INODE Page List` 和 FSP_HDR 页的 `File Space Header` 了。
#### List Node For INODE Page List
上面说过,INODE 页是表空间的第一组(第一个区)的第三个页,里面的核心结构式 Inode Entry, 用来描述段信息,但这样一页只能有 85 个 Inode Entry, 如果一张表里的段数量超过85个(索引数量超过 42 )时,就需要额外的 INODE 页来存储这些 Inode Entry 了, 根据这个 List Node For INODE Page List 字段就找到别的 INDOE 页,它的结构如下:

#### File Space Header
关于 FSP_HDR 页面,前面也说过了,它类似于 XDES 页面,存储了本组 256 个区的信息,除此之外,他是表空间的第一个页面,因此还存储了表空间的一些通用信息,这些信息就被存储在 File Space Header 里,它的结构如下:
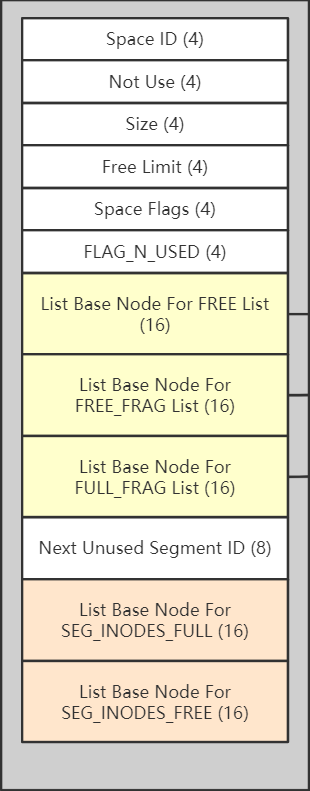
1. Space ID: 表空间 ID
2. Size:表空间拥有的页面数
3. FREE Limit: 未被初始化的最小页号,大于或等于该页号的区对应的 XDES Entry 都没被加入 FREE 链表, 每个表空间对应的其实是一个自增长的 ibd 文件(当然可以在建表时直接指定一个非常的文件),这些表空间中可能有大量未使用的区,InnoDB 不会把所有空闲区一股脑的加入 FREE 链表,而是会等到空闲区不够时,再加一批到链表中,加入到链表中的就是被初始化了,反之就是未初始化。
4. Space Flags: 一些标志字段
5. FRAG_N_USED: 类似于 Inode Entry 中的 NOT_FULL_N_USED, 表示 FREE_FRAG链表中有多少页面被使用了。
6. List Base Node for FREE List: 上面说 FREE 链表的根节点被保存在固定的地方,就是这。
7. List Base Node for FREE_FRAG List:FREE_FRAG 链表根节点。
8. List Base Node for FULL_FRAG List:FULL_FRAG 链表根节点。
9. Next Unused Segment ID: 每个段都有一个唯一 ID,这个字段表示下一个可以分配的段ID。
10. List Base Node for SEG_INODES_FULL:上面说,INODE 类型的页面可能有多个,由 `List Node For INODE Page List` 连接,这些 INODE 页也会依据有没有满链成两个链表:`SEG_INODES_FULL` 和 `SEG_INODES_FREE`, 这个字段就是 SEG_INODES_FULL 链表的头节点。
11. List Base Node for SEG_INODES_FREE: SEG_INODES_FREE 链表的头节点。
### 总结
最后,祭上大图吧

## 系统表空间
上面介绍了独立表空间的结构,它对应于数据库里的每一张表,但还有一些问题没有解决,比如如何确定哪张表对应哪个表空间等,这就需要系统表空间,一个 MySQL 服务只会对应一个系统表空间,它是 MySQL 服务的第一个表空间, Space ID 为 0, 记录了整个系统属性的相关信息,第一个组中的前七个页面类型分别为:
1. FSP_HDR
2. IBUF_BITMAP
3. SYS_insert buffer header
4. INODE_insert buffer root
5. TRX_SYS: 存储事务系统相关信息
6. SYS_first rollback segment: 第一个回滚段信息
7. SYS_data dictionary header: 数据字段头部信息
这里简单介绍与 Change Buffer 相关的 IBUF_BITMAP, SYS_insert buffer header 和 INODE_insert buffer root 以及数据字典相关的 SYS_data dictionary header, 其他字段都用于事务。
### Change Buffer
其实 IBUF_BITMAP 类型的页面在独立表空间也一直出现过,它实质上也是一棵 B+ 树,当我们往表中插入一条记录时,首先完整的记录会被插入到聚簇索引的叶子节点上,其次还需要更新所有二级索引,但这些索引随机处在表空间的不同地方,每次修改这些索引可能引起许多随机 IO,这会影响数据写入的效率,为此,当执行二级索引写入操作时,如果 InnoDB 发现二级索引对应的页面没在内存中,就会暂时把修改数据写到 Change Buffer 里,等服务器空闲时,再把数据写到二级索引对应的页里。
其中,系统表空间的 SYS_insert buffer header 字段用于存储 Change Buffer 的头部信息, INODE_insert buffer root 用于存储 Change Buffer 的根节点。
### 数据字典
InnoDB 的数据字典保存了许多重要的**元数据**, 包括:
- 表对应的表空间;
- 表中有多少列,每一列的类型是什么;
- 表中有多少索引,索引的字段,索引根节点对应的页面;
- 外键信息等……
这些信息是为了更好的管理用户信息而存在的,InnoDB 将他们放在一些内部表中,比较重要的有:
1. SYS_TABLES: 存储所有表信息
2. SYS_COLUMNS: 存储所有列信息
3. SYS_INDEXS: 存储所有索引xinx
4. SYS_FIELDS: 存储所有索引对应的列信息
5. SYS_TABLESPACES: 存储所有表空间信息
6. ……
其中,前四个表被称为四个基本表,使用这四个表,我们就可以获取其他系统表和用户数据了,比如更具表名就可以在 SYS_TABLES 表里获取到 Table ID, 根据 ID 到 SYS_COLUMNS 就可以获取到所有列信息,还可以到 SYS_FIELDS 和 SYS_INDEXS 获取到索引信息……
> 具体操作要看这四张表的具体结构
其他表可以使用这四张表定位,那这四张表该怎么定位呢?答案是硬编码,这四张表的信息被硬编码到了系统表空间的第七页上,也就是 SYS_data dictionary header 关于这一页的结构就不赘述了。
需要注意的是,这些内部系统表用户是不能直接访问的,但 InnoDB 为了用户能更好的使用存储引擎,提供了这些内部表的映射,对应数据库 `information_schema`, 这里面有一些 INNODB 开头的表, 如 `INNODB_TABLES` 的表结构如下:CREATE TEMPORARY TABLE
INNODB_TABLES(TABLE_IDbigint(21) unsigned NOT NULL DEFAULT ‘0’,NAMEvarchar(655) NOT NULL DEFAULT ‘’,FLAGint(11) NOT NULL DEFAULT ‘0’,N_COLSint(11) NOT NULL DEFAULT ‘0’,SPACEbigint(21) NOT NULL DEFAULT ‘0’,ROW_FORMATvarchar(12) DEFAULT NULL,ZIP_PAGE_SIZEint(11) unsigned NOT NULL DEFAULT ‘0’,SPACE_TYPEvarchar(10) DEFAULT NULL,INSTANT_COLSint(11) NOT NULL DEFAULT ‘0’
) ENGINE=MEMORY DEFAULT CHARSET=utf8;
```
- TABLE_ID: 表ID
- NAME:表名
- FLAG:有关表格式和存储特性的位级信息数据,包括行格式,压缩页大小(如果适用)以及DATA DIRECTORY子句是否与CREATE TABLE或ALTER TABLE一起使用等,参考 24.32.22 The INFORMATION_SCHEMA INNODB_SYS_TABLES Table
- N_COLS: 表中有多少列
- SPACE:表所属表空间 ID
- ROW_FORMAT:行格式,默认为 Dynamic
- ZIP_PAGE_SIZE: 压缩页大小
- SPACE_TYPE: 表所属的表空间类型。可能的值包括:System(系统表空间)、General(普通表空间)、Single(独立表空间)
- INSTANT_COLS:8.0 之后的新特性,表示插入的列的个数,参考 MySQL8.0 - 新特性 - Instant Add Column
总结
InnoDB 的完整数据存放在聚簇索引的叶子节点上,索引的一个节点就是一页,为了减少随机 IO,当表中的数据很多时,会一次性分配连续的 64 页,称为一个区,每个区由一个 XDES Entry 结构管理,根据区的状态,这些 XDES Entry 会链成不同的链表,链表头节点保存在表空间的第一个页面上,除此之外,为了尽可能保证叶子节点在物理内存上连续, InnoDB 把叶子节点和非叶子节点通过段分开,每个段由 Inode Entry 管理。
当定位到页后,InnoDB 还提供了页目录来提高页内检索速度。
MySQL 服务共有的信息被存储在系统表空间中,最重要的是 InnoDB 数据字典,通过它,我们才可以获取到表空间中的记录。