Kafka学习
本文最后更新于:2022年7月3日 下午
什么叫消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
为什么要用消息队列
- 提高系统响应速度使用了消息队列,生产者一方,把消息往队列里一扔,就可以立马返回,响应用户了。无需等待处理结果
处理结果可以让用户稍后自己来取,如医院取化验单。也可以让生产者订阅(如:留下手机号码或让生产者实现listener接口、加入监听队列),有结果了通知。获得约定将结果放在某处,无需通知。 - 提高系统稳定性
考虑电商系统下订单,发送数据给生产系统的情况。电商系统和生产系统之间的网络有可能掉线,生产系统可能会因维护等原因暂停服务。如果不使用消息队列,电商系统数据发布出去,顾客无法下单,影响业务开展。两个系统间不应该如此紧密耦合。应该通过消息队列解耦。同时让系统更健壮、稳定。 - 异步
比如我们在注册成功一般网站会给我们的邮箱发送一个邮件,如果是同步的进行邮件的发送,让系统完成邮件发送后才会给我弹出注册成功,如果有许多用户进行注册,对这个系统的压力和堆用户的反馈就不是很好,如果我们使用了消息队列,那么将消息进行发送后,由对应的邮件发送子系统进行发放,那么效率将会提高很多。 - 削峰
峰值的问题。在分布式系统中,一次分布式事务关联的是多个节点,其中每一个节点出现问题都会成为整个事务处理流程中的瓶颈。如果逻辑节点与数据库之间没有一个起到缓冲作用的节点,那就是每次操作都要访问数据库,对于MMO来说,一个玩家上线load几百K数据,一个服10万个玩家上线已经足够搞垮一个mysql节点了。如果直接搞垮还是比较好的结果,至少是前面的玩家确实登录上去了并且可以正常游戏,后面的玩家登录不上。但是很可惜,十年前开始流行的C10K说法就是在讲:并发量上来之后,会造成chain reaction,大量的并发不会直接挂掉你的mysql节点,但是会拖慢速度,降低吞吐量,一个玩家的请求由于处理时间太长,导致玩家放弃重试,但是对于后端来说,对该玩家之前的处理过程消耗的资源就全部浪费了,陷入恶性循环。 - 解耦
同异步,将系统成为两部分,降低了项目的耦合,增加了项目的可扩展性。
什么是kafka
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
kafka有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
kafka架构
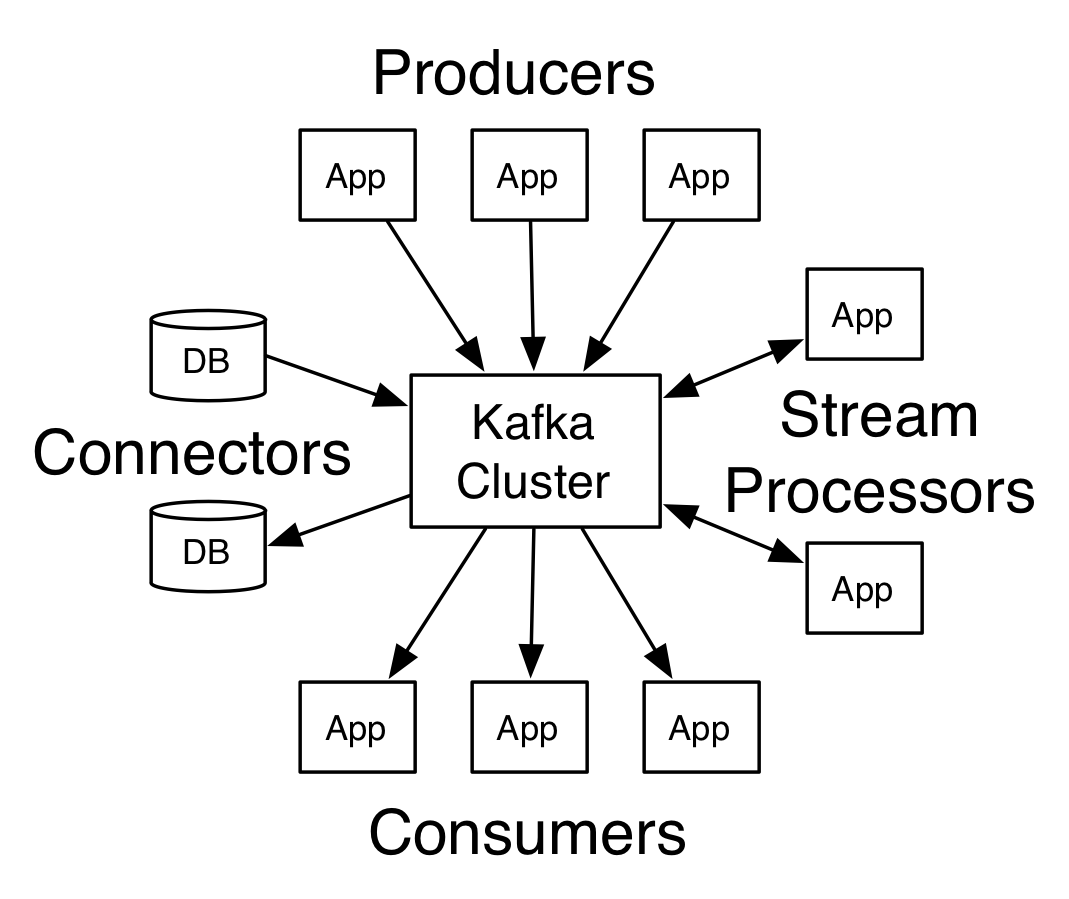
Kafka有四个核心的API:
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
Topic和Partition
Topic就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:
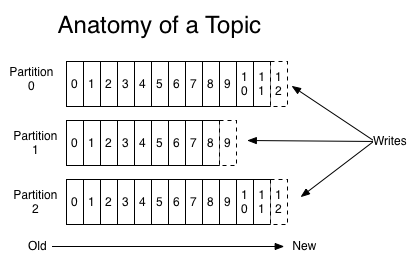
每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制. 举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题.
topic中的数据分割为一个或多个partition每个topic至少有一个partition,每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
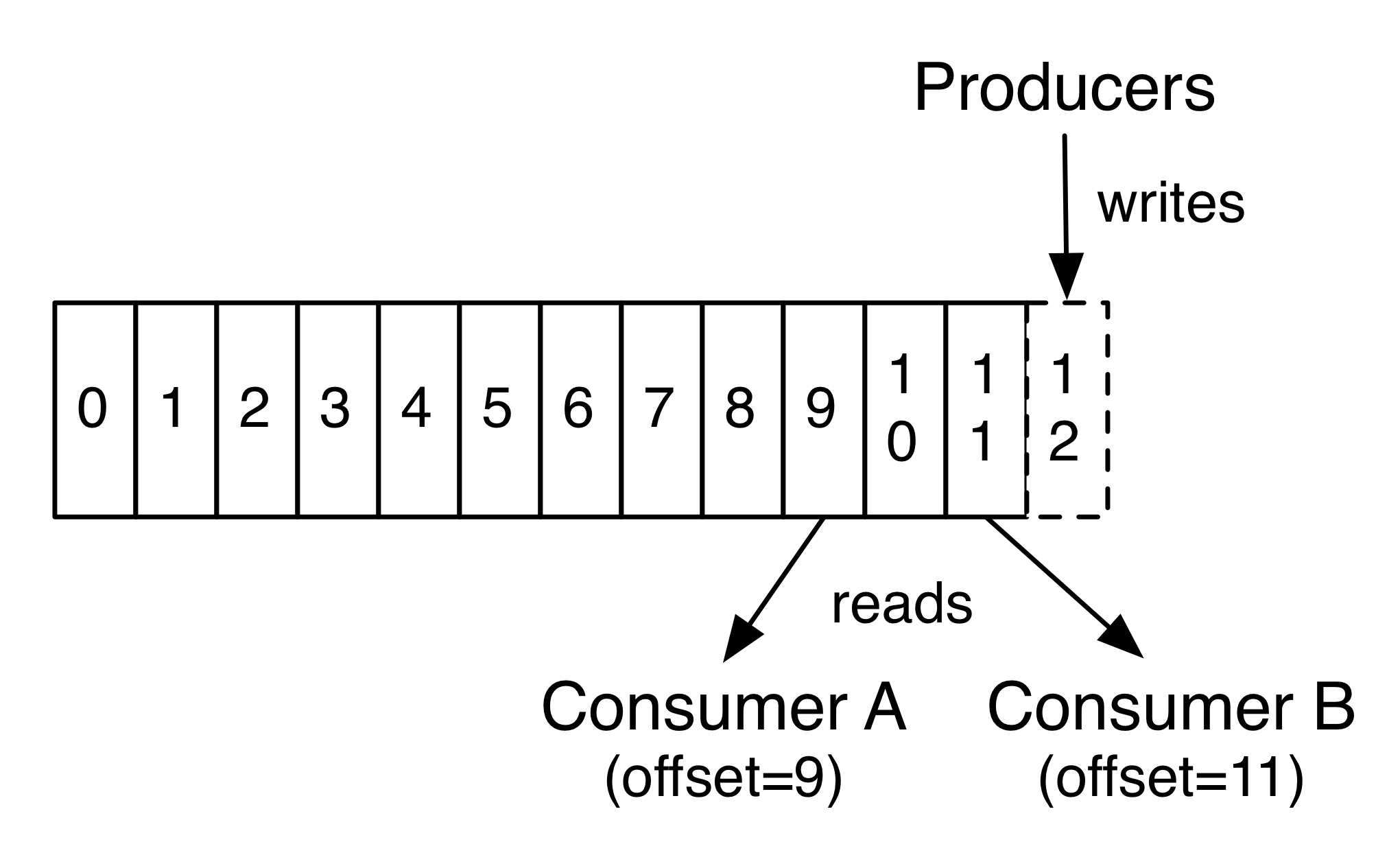
事实上,在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从”现在”开始消费。
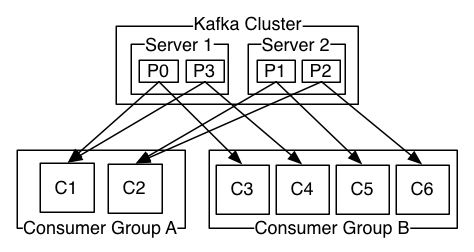
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个”逻辑订阅者”。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
- broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
kafka安装使用
建议使用docker-compose 进行安装,这里笔者也只说一下dockers-compose的安装方法
docker-compose.yaml
1 | |
然后我们运行
1 | |
之后我们可以新建一个topic看看是否部署成功
1 | |
确认部署后我们可以用命令行的方式创建一个生产者
1 | |
然后来一个消费者
1 | |
这个时候用生产者生产消息,可以看到消费者打印出了消息


kafka怎么保证数据可靠性
在kafka中topic只是一个虚拟的概念不是真实存在的,真实存在的是partition分区,这些分区才是实实在在的存储在硬盘上的数据。为了保证数据的可靠性,尽量不丢失数据。kafka使用了以下方法来实现数据的可靠性
我们都知道当我们要把数据通过生产者发送给kafka的时候会指定一个topic,首先生产者把生产的消息发送给topic,然后再发送到各个topic的分区partition,为了保证数据不丢失,我们就需要各个partition进行ack,如果生产者成功收到了ack,那么证明这次数据发送是成功的,否则的话证明这次数据的发送不成功,进行重发等操作。
但是这样做会引发问题:
什么时候发送ack
我们应该在什么时候发送ACK呢?是应该当分区的leader完成同步后就发送ACK,还是应该等待leader和follower都完成了数据同步才发送ACK呢?如果使用第一种方法的话,那么就会提高我们整个kafka的吞吐量,但是显而易见的,可能会对可靠性产生一点的影响,如果leader同步完之后就发送ACK的话,那么可能这个时候follower还没同步完成,leader挂了,那么就会造成数据的丢失。用第二种的话当然会在效率上有所损失,但是会提高我们数据的可靠性。但同时,第二种方法也会存在一些问题,我们在同步的时候是应该等待全部的follower都同步完在发送ACK还是当半数以上的follower完成同步就可以进行ack了呢。
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上就可以进行ACK | 降低延迟 | 选举新的leader的时候,容忍n台节点故障,需要2n+1个副本 |
| 全部发送完成才进行ACK | 选举新的leader,容忍容忍n台节点故障,需要n+1个副本 | 延迟高 |
Kafka 选择了第二种方案,采用第二种方案之后,设想以下情景:leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。这个问题怎么办?
为了解解决这个问题,kafka使用了ISR技术
ISR
Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集 合。当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower 长时间 未 向 leader 同 步 数 据 , 则 该 follower 将 被 踢 出 ISR , 该 时 间 阈 值 由replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR 中选举新的 leader。
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失, 所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡, 选择以下的配置。
- 0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还 没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
- 1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据;
- -1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会 造成数据重复。
HW和HEO(保证一致性)
HW(High Watermark)高水位
HEO(Log End Offset)记录结束偏移量
LEO指的是每个副本最大的offset
HW指的是消费者能见到的最大的offset,即ISR队列中的最小的LEO。
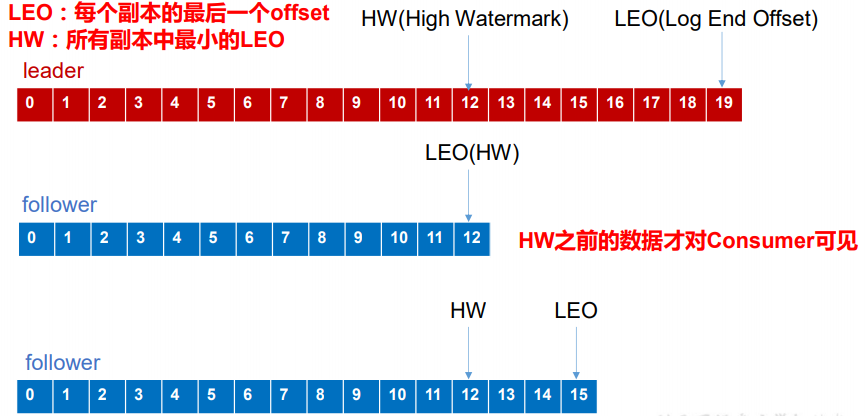
利用HW可以保证的是消费者消费信息的一致性,因为如果和上图一样不适用HW的话,那么可能leader可消费19条消息,然后leader挂了图中的第二个队列成为了leader,那么消费者又会发现,可消费的消息变成了12条,发生什么事了。就会导致消费者看起来消息的不一致,这是我们HW用来保证消费者消息一致性的,但是应该注意,使用HW并不能保证数据不丢失,数据丢失不丢失是上面ACK决定的,这里只能确定消费者消费的一致性。
(1)follower 故障
follower 发生故障后会被临时踢出 ISR,待该 follower 恢复后,follower 会读取本地磁盘 记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。 等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重 新加入 ISR 了。
(2)leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader,之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。 注意:新当选的leader不会把自己的HW之后的截取
精准一次性(exactly once)
将服务器的 ACK 级别设置为-1,可以保证 Producer 到 Server 之间不会丢失数据,即 At Least Once 语义。相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被 发送一次,即 At Most Once 语义。
At Least Once 可以保证数据不丢失,但是不能保证数据不重复;相对的,At Least Once 可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些非常重要的信息,比如说 交易数据,下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义。
幂等性结合 At Least Once 语 义,就构成了 Kafka 的 Exactly Once 语义。即:
At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。Kafka 的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在 初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而 Broker 端会对做缓存,当具有相同主键的消息提交时,Broker 只 会持久化一条。 但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。
kafka分区分配策略
一个 consumer group 中有多个consumer,一个 topic有多个partition,所以必然会涉及 到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。
Kafka 有两种分配策略,RoundRobin(轮询)和Range
Range
range (默认分配策略)对应的实现类是org.apache.kafka.clients.consumer.RangeAssignor 。
- 首先,将分区按数字顺序排行序,消费者按名称的字典序排序。
- 然后,用分区总数除以消费者总数。如果能够除尽,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区。
- 假设,有1个主题、10个分区、3个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者C1将会多消费一个分区,分配结果是:
- C1将消费T1主题的0、1、2、3分区。
- C2将消费T1主题的4、5、6分区。
- C3将消费T1主题的7、8、9分区
- 假设,有11个分区,分配结果是:
- C1将消费T1主题的0、1、2、3分区。
- C2将消费T1主题的4、5、 6、7分区。
- C2将消费T1主题的8、9、10分区。
- 假如,有2个主题(T0和T1),分别有3个分区,分配结果是:
- C1将消费T1主题的 0、1 分区,以及T1主题的 0、1 分区。
- C2将消费T1主题的 2、3 分区,以及T2主题的 2、3 分区。

RoundRobin
RoundRobin基于轮询算法对应的实现类是 org.apache.kafka.clients.consumer.RoundRobinAssignor
- 首先,将所有主题的分区组成
TopicAndPartition列表。 - 然后对TopicAndPartition列表按照hashCode进行排序某个 topic。
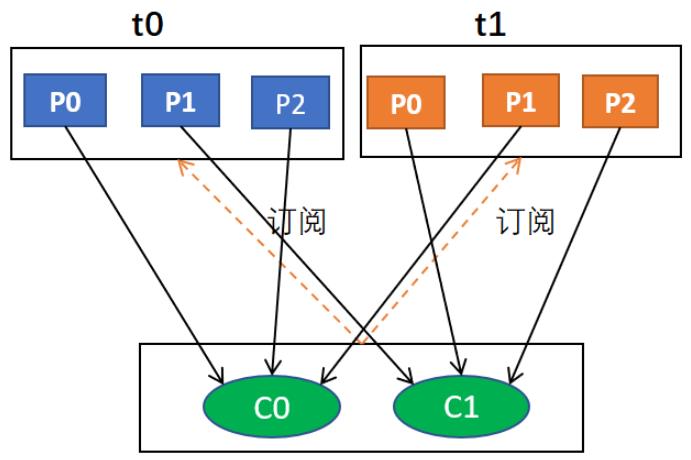
假设,有两个消费者C0和C1,两个主题T0和T1,每个主题有3个分区,分配结果是:
- C0将消费T0主题的0、2分区,以及T1主题的1分区。
- C1将消费T0主题的1分区,以及T1主题的0、2分区。
如何维护offset
为了保证一个Consumer Group中的consumer从一个Topic的多个Partition中消费消息时,保证offset的准确定,offset的存储在Zookeeper内是保存在 Consumer Group下的,格式:ConsumerGroup+Topic+Partition。
Kafka 0.9 之前的版本,Consumer默认将offset保存在Zookeeper中,从0.9 版本开始,Consumer默认将offset保存在 Kafka一个内置的 Topic中,该topic为 __consumer_offset。
1 | |
消费者生产者API使用
一般生产者
首先我们在kafka中创建了一个topic名称为
first,之后我们JAR包进行导入1
2
3
4
5
6
7<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.0</version>
//具体版本看自己的安装版本
</dependency>然后我们启动一个控制台的消费者
1
kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic first然后Java写代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
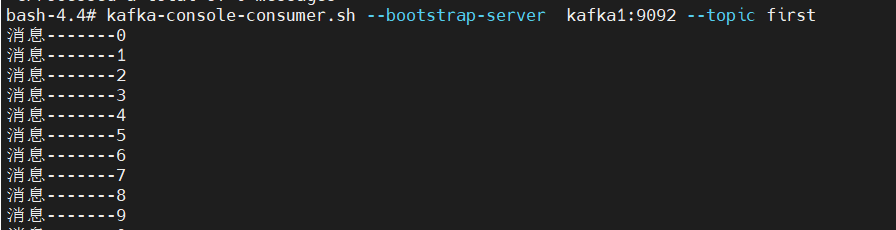
29public class MyProducer {
public static void main(String[] args) {
Properties properties = new Properties();
//kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kklll.cn:9092,kklll.cn:9093,kklll.cn:9094");
//ACK级别
properties.put(ProducerConfig.ACKS_CONFIG, "all");
//重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 1);
//批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//RecordAccumulator 缓冲区大小
properties.put(ProducerConfig.RECEIVE_BUFFER_CONFIG, 33554432);
//序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
//发送消息
producer.send(new ProducerRecord<String, String>("first", "消息-------" + i));
}
producer.close();
}
}可以看到我们控制台生成了消息
带回调的生产者
1 | |
自定义分区器
自定义分区器可以将消息进行分区,这样可以的实现我们自己定义分区的规则。
首先我们需要新建实现
partitioner的类,实现接口中的方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}其次我们需要在新建连接的时候把分区器的累写入到properties中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class CustomPartitionProducer {
public static void main(String[] args) {
Properties properties = new Properties();
//kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kklll.cn:9092,kklll.cn:9093,kklll.cn:9094");
//ACK级别
properties.put(ProducerConfig.ACKS_CONFIG, "all");
//重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 1);
//批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//RecordAccumulator 缓冲区大小
properties.put(ProducerConfig.RECEIVE_BUFFER_CONFIG, 33554432);
//序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
//设置分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.kklll.zookeeperlearn.kafka.partition.MyPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("aa", "测试信息", "消息-------" + i), (metadata, exception) -> {
//有异常的话处理异常,否则处理成功信息的metadata
if (exception == null) {
System.out.println(metadata.partition() + "-------" + metadata.offset());
} else {
exception.printStackTrace();
}
});
}
producer.close();
}
}
消费者代码
1 | |
消费者进行手动offset提交
同步提交
1 | |
异步提交
1 | |
自定义存储offset
Kafka0.9版本之前,offset 存储在 zookeeper,0.9 版本及之后,默认将 offset 存储在Kafka 的一个内置的 topic 中。除此之外,Kafka 还可以选择自定义存储 offset。
offset 的维护是相当繁琐的,因为需要考虑到消费者的Rebalace。 当有新的消费者加入消费者组、已有的消费者推出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做Rebalance。
消费者发生Rebalance 之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的 offset 位置继续消费。
要实现自定义存储 offset,需要借助ConsumerRebalanceListener
1 | |
自定义拦截器
首先我们要定义自定义的拦截器
1 | |
1 | |
然后我们写一个带拦截器的生产者
1 | |
就好了